Compare up to
Accurate 
Sophisticated data matching algorithm
Fast 
You will be amazed
Secure 
Install locally and keep your data safe
Easy to use 
Intuitive and optimized tools
Overcome complex problems that come with large numbers of data records, multiple data sources and errors in the original data with tools that are automated, optimized and that give you a clear visual representation of your data.
Improve time efficiency with a high-quality data management tool

Speed up data preparation, matching, cleansing, profiling, and duplication from various and multiple data sources.

User-friendly interface that allows you easy and fast data processing with visual tools that do not require programming knowledge.
Integrate, profile, link and prepare data for identification of potential problems to prevent negative influence on your future business decisions.
Accelerate the process of matching based on any conditions you need with acquiring the most accurate results and skip unnecessary steps which are required by conventional methods.

Highly sophisticated data matching algorithms gives you results of high-end complex calculation automatically in an easily understandable value of match probability.

Improve data quality with ultra-fast and intuitive cleansing, standardization, enrichment and deduplication tools that allow you to easily remove all unnecessary information from your data.

DataExcelerate API
Easy to integrate into your applications of any type

Improve critical spots in your process that are slowing you down and makes a negative influence on your productivity.

Maximize your software quality and performance with optimized and proven data processing functionalities provided by DataExcelerate API.

DataExcelerate API provides you with all the necessary functionalities for data processing.

It is very easy to implement because it's a standard REST API and comes with Swagger documentation.
Solutions

Advanced Data Matching
Compare Up to 200 Million Records





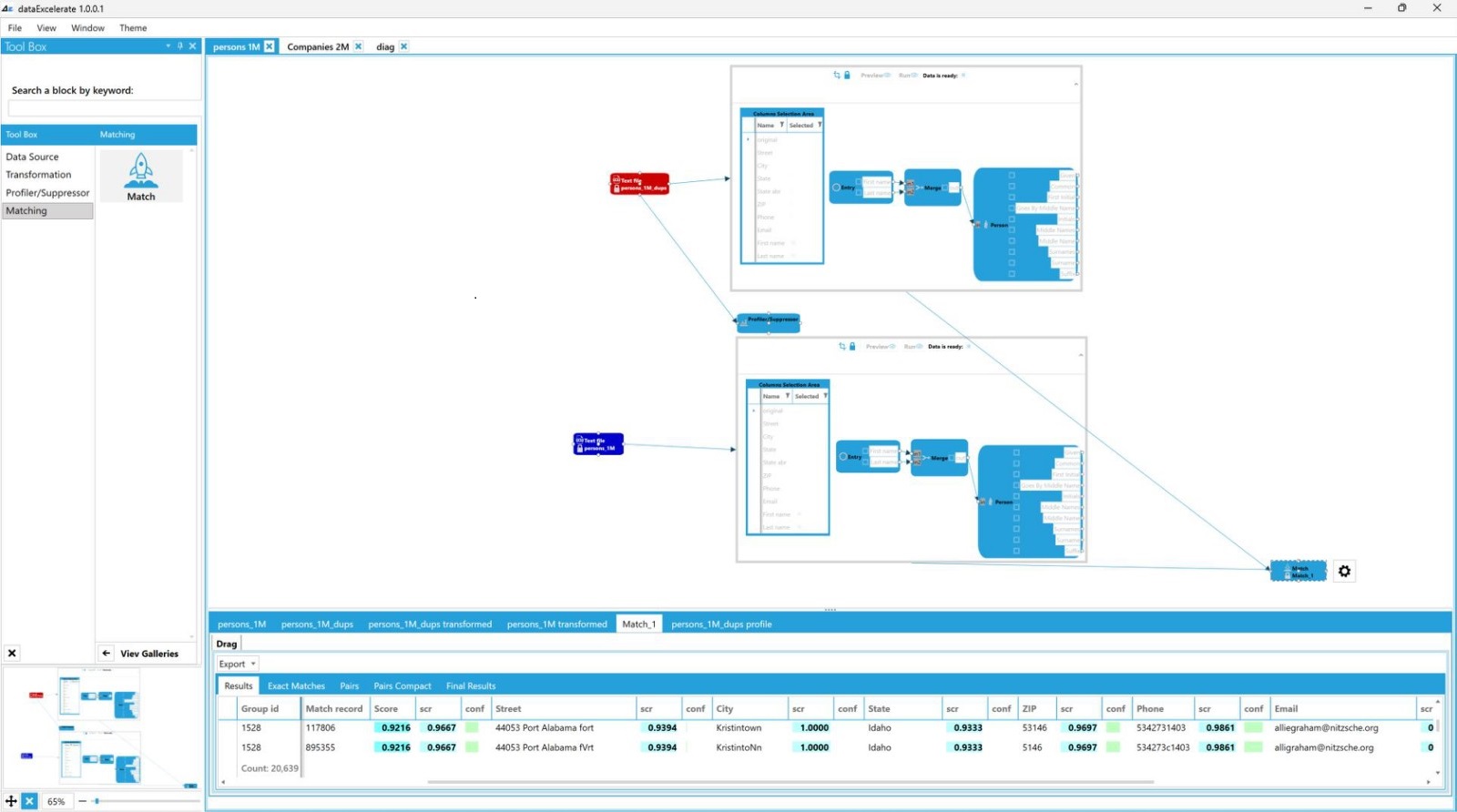
Data Matching
New Generation Data Matching
Data Matching is also known as record linkage is the process of finding records that refer to the same entity and addresses them accordingly.
Accelerate the process of matching based on any conditions you need with acquiring the most accurate results.
Find matches, remove duplicates, enrich records avoiding obstacles caused by them.


Detect duplicate records within a single database or from multiple data sets that do not have common entity identifiers.

You do not need to waste time anymore on outdated and complex approaches that require you to manually input and assign a relative weight for each attribute to get Total Match Weight.
We give you an automated solution that allows you to easily identify matches from a list of highly precise possible matches ordered descendingly by match confidence.

Match confidence is based on the result of high-end complex calculation which uses highly sophisticated proprietary data matching algorithms.
Data Profiling
Explore data efficiently
Data profiling is the key step for increasing the data accuracy level.
Systematically analyze data from multiple and various data sources.
Easily research data to gain key information for understanding data challenges early and solve them accordingly minimizing project costs, (delays) and time needed to realize your goals.


Confirm that data meets the requirements of standards and patterns you need.

Gain better searchability and easy access to concrete summarized validated data you can rely on.
Improve usability of data by assigning it into well-organized units providing you the base resources for your future operations.
Find and address the risk in the migration and integration data process.

Identify the value and potential of your data and find the best strategy to maximize its usage.
Data Cleaning
Prevent unnecessary data to influence analysis and provide inaccurate results
Data cleaning is a foundational element of data science and plays an important role in the analytical process and uncovering reliable answers.
Collecting data from disparate sources that can be generated by manual input from users, can carry many mistakes and incorrectly inputted information.

Find and fix spelling and syntax errors, standardize data sets, correct mistakes such as empty fields and identify duplicate data.
We provide you with tools for easy and visual analysis to ensure the generation of highly accurate data.

Create standardized and uni-form data sets and optimize them for analysis to allow your business intelligence or data analytics teams to find information more efficiently.

Prepare data for analysis by removing or modifying data that is incomplete, incorrect, irrelevant, duplicated or improperly formatted.

Maximize data sets accuracy without necessarily deleting information.
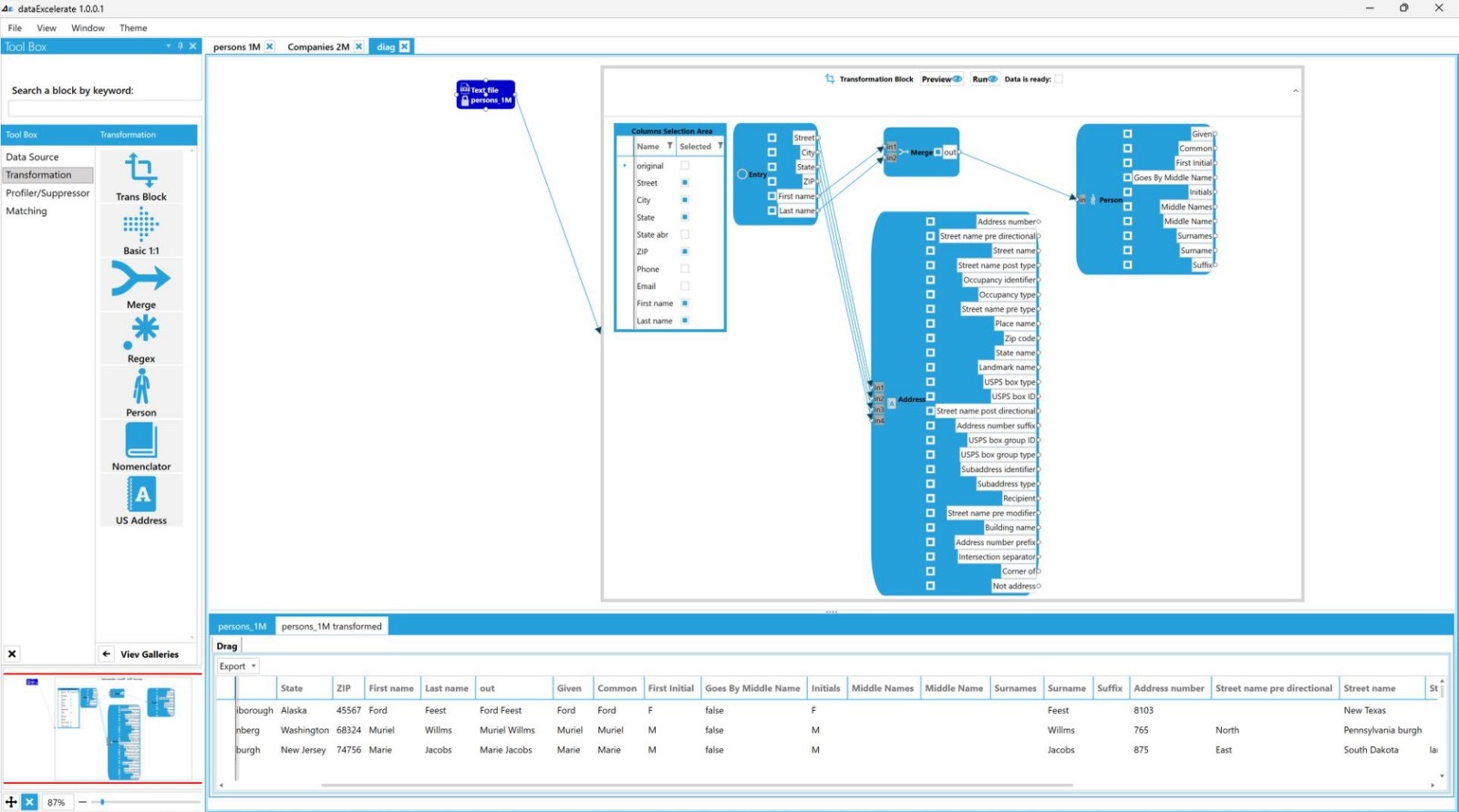
Data Preparation
Increase accuracy and speed up data analytics
Data may come from many different sources and in many forms.
Data preparation is a process of converting raw data into a well-organized structure that is optimized for analysis. This is the first and most crucial step in every data analytics project.
Our visual tools are designed to facilitate this process and give an easy way for data manipulation that does not require programming or IT skills.

Get full and detailed specifications of your (input) data and understand the information available with statistical results that come from automated complex calculations that run in the background.

Automate preparation work with creating customized workflows that can be used for processing the same operations of different datasets.
Easily find data that should be removed, corrected or extended.
Data Deduplication
Improve productivity by removing duplicated data
Data deduplication is a process that eliminates redundant data in a data set.
In the process of deduplication data is analyzed to identify duplicates and remove them to ensure a single instance of reliable data, improving analysis time and making the process less costly.

Find duplicate records for the same entity across multiple sources create and enriched an golden record.

Invest in your future by improving the quality of your data.
Data Enrichment
Maximize the value of your data
Data enrichment is the process of connecting the best pieces of data from multiple and various data sources into a single instance that best benefits your goals.
It is very important to have detailed and updated data. Having quality data is key to great business decisions that increase profitability and growth.

Create the best golden records.
Data enrichment processes need to run continuously to prevent having outdated information.
Keeping data updated is a very complex and important task.
Automate this process and get the best data quality for your business needs with easy-to-use visual tools that do not require programming or IT knowledge.
Data Standardization
Tailor data to your standard
Data standardization is the process of converting data to a structure of common format specifics to your business needs.
Collecting data from multiple sources to generate quality information can be complex because data is not always uniform across different data sources.

Ensure internally consistent data that can be easily understandable and used by everyone in your organization.

Organize data into a clear uniform format, with logical and consistent definitions that suit your organization's standard and make your analytics and reporting easier.